图相似问题#
图相似性问题是指在图论中研究的一个重要问题,它涉及到比较两个或多个图之间的相似程度或差异程度。 这个问题在许多领域都有广泛的应用,包括生物信息学、社交网络分析、图像识别等。 在图相似性问题中,通常需要定义一个度量或指标来衡量图之间的相似性。一些常见的图相似性度量包括:
图结构比较:考虑图的结构信息,比较节点之间的连接关系。常用的方法包括计算节点的邻居、子图、路径等结构特征,并根据这些特征计算图之间的相似度。
图的频谱特征:利用图的谱分解特征来比较图之间的相似性。谱方法将图表示为其邻接矩阵的特征值或特征向量,然后使用这些特征来比较图的相似性。
子图匹配:寻找两个图之间的相同子图或最大匹配子图。这种方法通常用于发现图中的共同模式或结构。
图的距离度量:定义图之间的距离或相似度度量,例如编辑距离、哈密尔顿距离、树编辑距离等。这些度量可以衡量图之间的结构差异或相似度。
图的嵌入表示:将图映射到低维向量空间中,然后利用向量表示来比较图之间的相似性。这种方法通常使用图嵌入技术,如节点嵌入或图嵌入。
图相似性问题的解决方法取决于具体的应用场景和所关注的问题。 在实际应用中,常常需要综合考虑图的结构特征、频谱特征、距离度量等多方面因素,来全面评估图之间的相似性。
图同构(graph isomorphism)#
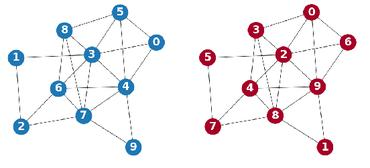
通过图同构可以来判断图之间的相似程度。 图同构描述的是图论中两个图的完全等价关系,在图论的观点下,两个同构的图被当作同一个图来研究。 只有节点数目相同的两个图才有可能同构。 称两个简单图 \(G\) 和 \(H\) 是同构,如果存在一个双射(bijective)\(f\),使得图 \(G\) 中任意两个节点 \(i, j\) 相连接,当且仅当 \(H\) 中对应的的两个节点\(f(i), f(j)\) 相连接。 两个图称为同构如果他们之间存在这样的同构映射关系。 同构的两个图有相同的图结构,因此必然是相似的两个图,然而非同构图也可能有相似的图结构,比如下面的第二个例子

特征映射(feature map)#
为了更好的衡量图相似度,引入了特征映射(feature map)的方法, 特征映射 \(\phi\) 将每个图 \(G\) 映射成高维空间的特征向量 \(\phi(G)\),图相似度通过核函数 \(K\) (kernel function) 来衡量,核函数 \(K\) 的作用是计算特征向量之间的距离,比如通过内积计算,此时核函数定义为,
需要注意的是特征映射的方法不仅仅适用于图相似度问题,更多的应用在机器学习中的分类问题上。 接下来我们将介绍如何使用高斯玻色采样来构造图的特征映射。
GBS 采样和图相似问题#
文献[1]阐述了两个图是同构的当且仅当他们对应的高斯玻色采样概率分布相同, 但是实际实验中图G的GBS的所有样本概率分布是很难得到的, 其原因在于 样本所在的量子态空间随图的规模是指数增大的,那么很多量子态对应的概率是指数下降的,因此在有限的采样次数下很难反映出整体的概率分布。 为了避免这个问题, 我们引入粗粒化采样(coarse-grain)的方法[1], 粗粒化方法将一个全排列对应的所有样本放入同一个样本集合里,这个样本集合称为orbit。 比如样本 \(S_1=(0,2,3,0,1,2,0)\) 和 \(S_2=(0,3,2,0,2,1,0)\) 属于同一个orbit \((3,2,2,1)\)。
尽管一个orbit里面包含了许多样本,但是orbit的数量依旧很多,因为末态的数量是随着规模指数增加的, 因此我们可以进一步进行粗粒化[2]。 这里我们引入事件(event)的概念, 用 \(E_{k,n}\) 表示, 它是由这些样本组成的集合, 每个样本总光子数为 \(k\) 个同时每个模式最大光子数不超过 \(n\) 个。 比如上面的 \(S_1\) 在事件 \(E_{8,3}\) 中,而不在 \(E_{8,2}\) 中,因为最大光子数为3。 下图是一个具体的例子
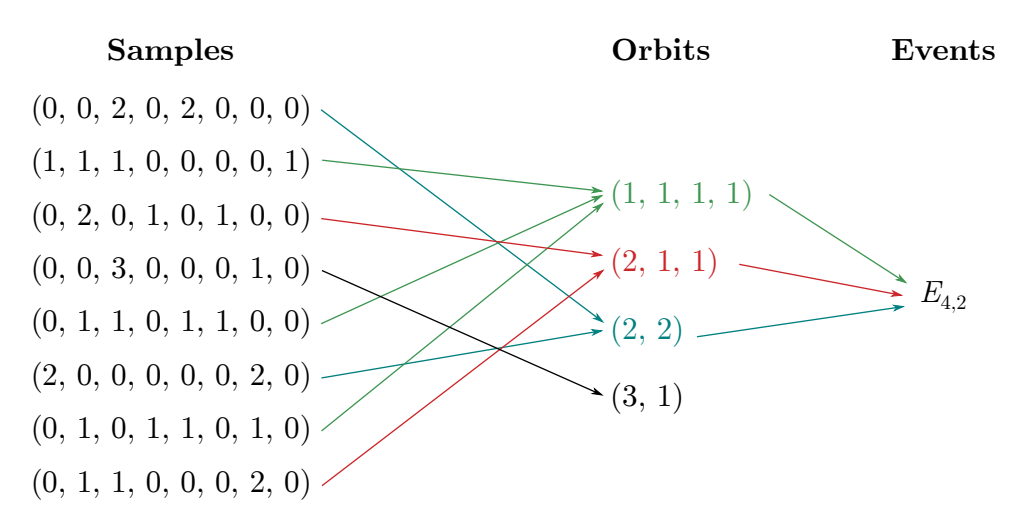
这里我们用 \(p_{k,n}(G)\) 表示图G通过高斯玻色采样采到一个样本在事件 \(E_{k,n}\) 的概率,现在我们来构造对应的特征映射,它将一个图G映射到一个高维的向量, 向量的每个元素是对应的样本事件概率 \(E_{k,n}\),
\(k = \{k_1, k_2,..k_D\}\) 表示一组总的光子数, \(n\) 表示每个模式对应的最大光子数
算法说明#
将图\(G\)对应的邻接矩阵编码到高斯玻色采样设备中并产生N个样本。
给定一组总光子数 \(k = \{k_1, k_2,...,k_D\}\) 和每个模式对应的最大光子数n, 遍历所有样本, 将样本放入对应事件 \(E_{k_i,n}\) 中, 将每个事件包含的样本数记为 \(N_i\)。
计算每个事件 \(E_{k_i,n}\) 对应的概率, 这里用样本概率替代理论概率 \(\tilde{p}_{k_i,n}(G) = \frac{N_i}{N}\approx p_{k_i,n}(G) \)。
构造特征映射向量 \(f_{{k},n}(G) = (\tilde{p}_{k_1, n}(G), \tilde{p}_{k_2, n}(G),...,\tilde{p}_{k_D, n}(G))\)。
数据集说明#
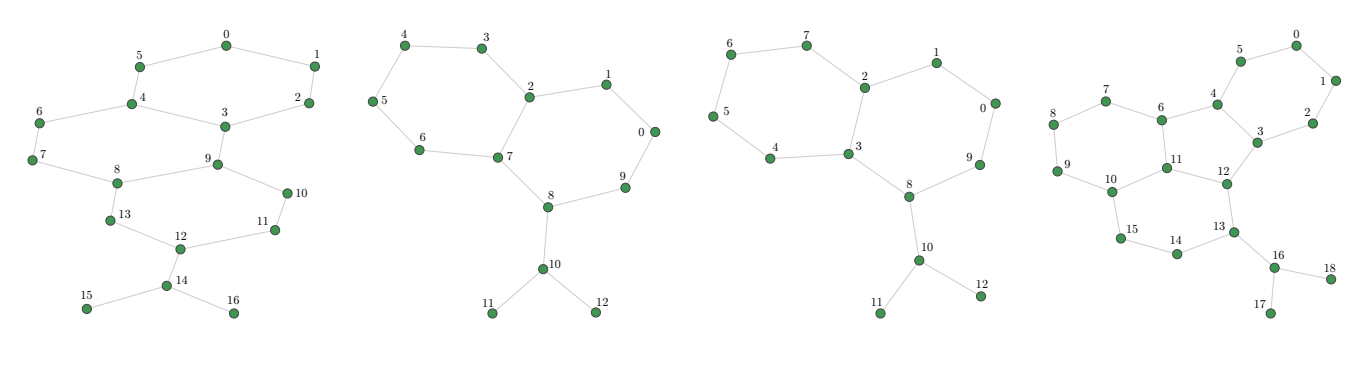
这里我们使用mutag数据集的前四个图来作为例子,如下图所示,下图中第一个和第四个图是相似的, 第二个和第三个图是同构的, 我们将通过高斯玻色采样实现四个图的分类。其他数据可以在这里找到
代码演示#
import deepquantum.photonic as dqp
import torch
## orbit sample
def orbit_sample(orbit, samples):
"""Pick the sample belonging to the given orbit"""
orbit_sample_dict = {}
set_orbit = sorted(orbit)
for k in list(samples):
temp = list(filter(lambda x: x != 0, list(k)))
temp = sorted(temp)
if temp == set_orbit:
orbit_sample_dict[k] = samples[k]
return orbit_sample_dict
## event sample
def event_sample(k, n, samples):
"""Pick the sample belonging to the given even E_{k,n}
k: total number of photons in all modes
n: maximum number of photons for single mode+1
"""
orbit_list = integer_partition(k, n - 1)
orbit_list_sort = [sorted(orbit) for orbit in orbit_list]
orbit_sample_list = [{} for i in range(len(orbit_list))]
for i in list(samples):
temp = list(filter(lambda x: x != 0, list(i)))
temp = sorted(temp)
if temp in orbit_list_sort:
idx = orbit_list_sort.index(temp)
orbit_sample_list[idx][i] = samples[i]
return orbit_sample_list
def integer_partition(m, n):
"""Integer partition"""
results = []
def back_trace(m, n, result=None):
if result is None:
result = []
if m == 0: # 如果 m 等于 0,说明已经找到了一个分解方式,将其加入结果列表
results.append(result)
return
if m < 0 or n == 0: # 如果 m 小于 0 或者 n 等于 0,说明无法找到满足条件的分解方式,直接返回
return
back_trace(m, n - 1, result) # 不使用 n 进行分解,继续递归
back_trace(m - n, n, result + [n]) # 使用 n 进行分解,继续递归
back_trace(m, n)
return results
## feature map
def feature_map_event_sample(event_photon_numbers, n, samples):
"""Map a set of graph G to the feature vectors using the event examples."""
all_feature_vectors = []
for sample in samples:
count_list = []
total_num_samples = sum(sample.values())
for k in event_photon_numbers:
e_k_n = event_sample(k, n, sample)
temp_sum = 0
for i in range(len(e_k_n)):
temp_sum = temp_sum + sum(e_k_n[i].values())
count_list.append(temp_sum)
feature_vector = (torch.stack(count_list) / total_num_samples).reshape(1, -1)
all_feature_vectors.append(feature_vector.squeeze())
return torch.stack(all_feature_vectors)
先将四个mutag数据图对应的邻接矩阵编码放入高斯玻色采样线路中, 使用 deepquantum.photonic.GraphGBS.measure 进行采样,默认使用5条马尔可夫链进行采样, 每条链采样次数为30000次, 我们对应的采样结果为
\(\text{samples}\_1\), \(\text{samples}\_2\), \(\text{samples}\_3\), \(\text{samples}\_4\), 这里我们直接读取已经采样数据。
a_1 = dqp.utils.load_adj('mutag_1_adj')
a_2 = dqp.utils.load_adj('mutag_2_adj')
a_3 = dqp.utils.load_adj('mutag_3_adj')
a_4 = dqp.utils.load_adj('mutag_4_adj')
samples_1 = dqp.utils.load_sample('mutag_1_sample')
samples_2 = dqp.utils.load_sample('mutag_2_sample')
samples_3 = dqp.utils.load_sample('mutag_3_sample')
samples_4 = dqp.utils.load_sample('mutag_4_sample')
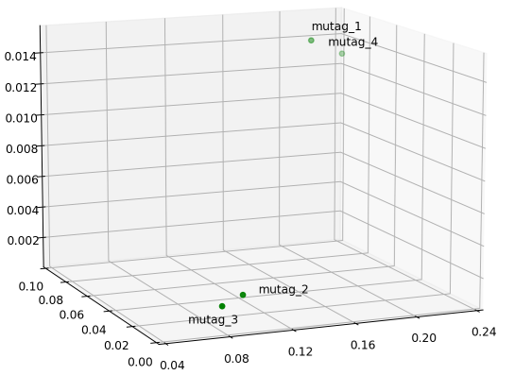
现在将每个样本的结果通过特征映射函数feature_map_event_sample处理, 每个图都映射成一个高维矢量,这里我们采用事件\(E_{6,2}, E_{8,2},E_{10,2}\)作为分类标准, 得到一个三维的矢量, 因为我们的光子截断数为2,为了更好的分类所以这里采用三维矢量映射而不是二维,
映射后的矢量如下图所示。
feature_vec = feature_map_event_sample([6, 8, 10], 2, [samples_1, samples_2, samples_3, samples_4])
print(feature_vec)
tensor([[0.1949, 0.0708, 0.0147],
[0.1048, 0.0183, 0.0014],
[0.0881, 0.0141, 0.0011],
[0.2302, 0.0862, 0.0132]])
将下面三维矢量可视化如下图所示
附录#
[1] K. Bradler, S. Friedland, J. Izaac, N. Killoran, and D. Su, arXiv:1810.10644 (2018).
[2] K. Bradler, R. Israel, M. Schuld, and D. Su, arXiv:1910.04022 (2019).